|
1. Inleiding
Dit verslag is een tentamen vervangende taak voor het vak computerveiligheid (in404) aan de Technische Universiteit Delft. Het doel van het verslag is het gebruik van self modifying code te onderzoeken. Ook zal worden gekeken naar de toepasbaarheid van self modifying code binnen het kader van de computerveiligheid. In het verslag zal een korte uitleg worden gegeven van self modifying code (H1), daarna zal er op de techniek ingegaan worden (H2), voor een aantal toepassing zal worden uitgelegd waarom self modifying code wordt gebruikt of kan worden gebruikt (H3), de nadelen en moeilijkheden die bij het gebruik van self modifying code komen kijken zullen aan bod komen (H4), de mogelijkheden voor de toekomst zullen onder de loep worden genomen (H5) en tenslotte zullen enkele aanbevelingen gedaan worden en conclusies worden geformuleerd (H6). Self modifying code is een programmeertechniek waarbij een programma tijdens het uitvoeren de logische volgorde van zijn eigen instructies veranderd of instructies toevoegt. Dit kan doordat de uit te voeren instructies zich in hetzelfde geheugen bevinden als de data die het programma moet verwerken. De instructies worden gezien als data. De eerste computers hadden programma en invoer strikt gescheiden. Eerst werden de instructies in de computer ingevoerd. Dan werden, tijdens het draaien van het programma, de data ingevoerd die door de instructies verwerkt werden. Hier kwam halverwege de jaren 40 verandering in. In een paper over de EDVAC (Electronic Discrete Variable Automatic Computer) herintroducerende John Von Neumann het idee voor een stored program computer. Von Neumann suggereerde dat de instructies voor de computer, die voor die tijd op ponsband of plugboards stonden, konden worden opgeslagen in het geheugen van de computer als nummers en door een centrale verwerkingseenheid konden worden behandeld op dezelfde manier als numerieke data.
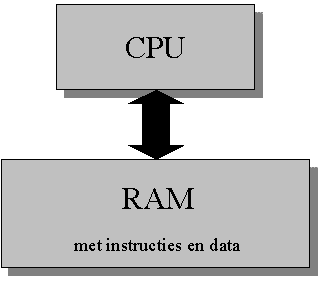 figuur 1.1 Door deze niet strikte scheiding tussen code en data is het mogelijk code als data op te vatten en vice versa. Totaal zijn er dus vier verschillende opvattingen.
De eerste twee van deze situaties zijn "normaal". Voor de overgebleven twee, die voornamelijk per ongeluk gebeuren, volgt nu een kleine uitleg. Code als data opvatten betekent dat we bepaalde operaties kunnen gaan toepassen op code alsof het om getallen gaat. Als dit per ongeluk gaat kan het zeer vervelende consequenties hebben. Als bijvoorbeeld de 'code', verkregen na de operatie (bijvoorbeeld een optelling), geen geldige code meer is, dan is de kans groot dat de computer vast loopt. Data als code opvatten betekent dat we er vanuit gaan dat een bepaald stuk data geldige code is. Dat wil zeggen dat de computer de data kan uitvoeren zonder problemen. Ook dit kan vervelende consequenties hebben als de data geen geldige code is. Meestal is het uitvoeren van data of het veranderen van code een niet bedoelde operatie. Programmeertalen beperken de kans op dit soort fouten, doordat er beveiligingen zijn ingebouwd, zodat deze verwisseling niet eenvoudig kan gebeuren. Hierbij wordt ervoor gezorgd dat code statisch is en data dynamisch. Het opvatten van instructies als data is echter een methode die gebruikt kan worden om instructies dynamisch vast te leggen. Dit wordt ook wel 'voor de voet programmeren' of 'dynamic code generation' genoemd. In dit verslag zullen we de term 'self modifying code' gebruiken. Self modifying code werd vroeger al veel gebruikt. Het werd gebruikt om programma's kleiner en sneller te krijgen. Door de groei van beschikbaar geheugenruimte en de versnelling van processoren zijn deze argumenten minder zwaar gaan wegen. Programma's werden groter, complexer en er kwam een noodzaak om programma's te beschrijven in hogere programmeertalen. Op het moment zijn er geen hogere programmeertalen beschikbaar die self modifying code gebruiken. |
||||||||||||
|